一、图像特征码计算优化方式前一章节目录的图像特征码获取优化算法是根据像素数的三元色标值的,有时,图像小量的像素数差别很有可能影响鉴别結果 。有二种优化算法能够使鉴别实际效果更强:
- 将面部图像尺寸设定为适度的标值(一般越低越好),那样更能突显面部的特点,而省去许多影响项 。除此之外,获取初始特点组后,应用PCA特征提取技术性对初始特点组开展进一步生产加工,转化成最后的特点组,进而能够更好地定性分析面部 。
- 在规范欧氏距离的基本上品以权重值 。有二种计算方式:每地区清晰度设定不一样的权重值;设定总体权重值,使面部图像引流矩阵的差得分匀称化 。这儿应用第二种方式 。
离散系数指标值有:全距(偏差)指数、平均差指数、标准差指数和标准差系数等 。常见的是标准差系数,用CV(Coefficient of Variance)表明 。
CV(Coefficient of Variance):标准偏差与平均值的比例 。
用公式计算表明为:CV=σ/μCV=σ/μ
计算公式计算:
- 偏差(全距)指数:Vr=R/X′Vr=R/X′ ;
- 平均差指数:Va,d=A.D/X′Va,d=A.D/X′;
- 标准差指数:V标准差=标准差/X′V标准差=标准差/X′ ;
- 标准差系数:V标准偏差=标准偏差/X′V标准偏差=标准偏差/X′;
—-百科
变异系数能够清除由于平均值不一样在基因变异水平较为中造成的影响 。变异系数越小,数据信息离均值的偏移水平越小;相反,变异系数越大,数据信息离均值的偏移水平越大 。
这儿对变异系数开展改善,将标准偏差用标准差替代,随后将改善的变异系数的到数做为计算欧氏距离的调整指数,那样做的实际效果是:将偏移水平很大的数据信息授予较小的权重值,将偏移水平越小的数据信息授予很大的权重值中 。最终将规范欧氏距离乘于调整权重值,进而完成差别平均化,让改善后的欧氏引流矩阵能够更好地定性分析面部总体差别 。
三、编码实例 def get_distance(img,findimg): newsize=(21,21) fimg=cv2.resize(findimg,newsize) img = cv2.resize(img,newsize) my_img=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY) my_fimg = cv2.cvtColor(fimg, cv2.COLOR_BGR2GRAY) # PCA特征提取 pcaimg = mlpy.PCA() pcaimg.learn(my_img) pca_img = pcaimg.transform(my_img,k=1) pca_img=pcaimg.transform_inv(pca_img) pcafimg = mlpy.PCA() pcafimg.learn(my_fimg) pca_fimg = pcaimg.transform(my_fimg,k=1) pca_fimg = pcafimg.transform_inv(pca_fimg) # 计算根据总体权重值的欧氏距离 return get_EuclideanDistance(pca_img,pca_fimg)其他一部分编码与上一节同样 。
运作实际效果:
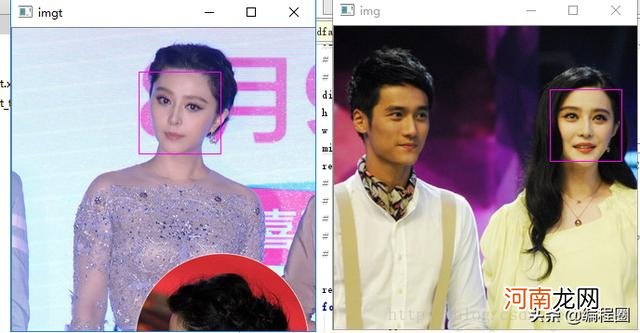
文章插图
【降维和变异系数提升识别效果 变异系数怎么算】来源于:冯耀宗blog,热烈欢迎共享文中!
- 一天中非常容易长肉的3个时间段,减肥瘦身人士若能避开,休重悄悄的降下来
- 玉米须如何降血糖 民间降血糖偏方全集
- 高血压并不是忽然来临,“三绿、三白”勿贪嘴,血压或会渐渐地降下来
- 车前草和鱼腥草泡水喝的功效与作用 车前草和鱼腥草能降尿酸吗
- 哪一种苏打水降尿酸
- 降尿酸最好的茶
- 常喝豆浆能够降血糖吗 豆浆怎么吃降血糖
- 糖尿病患者,若想降血糖,要谨记下午2不做,夜里3不吃,掌握下
- 吃什么水果可以降火消炎 上火会出现什么症状
- 推荐一款实用又方便的多功能升降茶几