你要做的就是告诉机器这些组合和文字的对应关系 , 接着让设备进行机器学习 。
通过这样的方式获得图片本身和图片中视觉概念(V1 , V2 , V3)的编码 。与视觉概念对应的文本 , 则通过文本编码器一一编码获得 , 例如图片标题、区域描述、或物体标签 。

文章插图
这一顿操作下来 , 小编也被绕晕了 。这玩意的作用有点像我们的眼睛 , 当我看到一个“书包” , 虽然我没见过这个款式的 , 但根据特征提取 , 我知道这个东西就是书包 , X-VLM就是这样一个工具 。
X-VLM可以在接收WeNet输出的文本信息后 , 将图像中相关联的物件提取出来 , 实现语言与视觉相关联 。到这里 , 我们可以实现让电脑知道我们说的话指的是图片里面的啥玩意了 。
第三步:追踪图像
在使用了X-VLM和WeNet之后 , 我们成功让设备听得懂咱们说的是啥玩意了 , 接下来要做的就是实现“追踪目标” , 听起来是不是很酷炫 , 有种开战斗机发射追踪导弹的感觉~
文章插图
相信不少小伙伴们都猜到了 , 这剩下的最后一个“STARK”就是用于实现图像追踪功能的AI工具 。
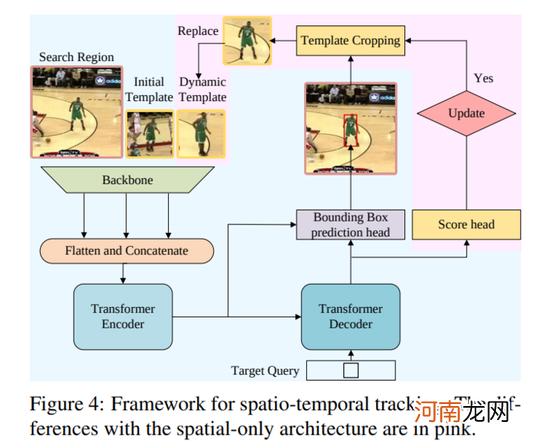
Stark是最新的SOTA跟踪模型 , 模型使用了transformer来结合空间信息以及时域信息 。
模型包括一个encoder , decoder以及prediction head 。其中encoder接收三个输入:当前帧图像 , 初始目标以及一个动态变化的模板图片 。由于模板图片在追踪过程中是动态变化 , 不断更新的 , 因此encoder可以同时捕获到目标的时域和空间信息 。
获取目标信息以后 , 工具会通过预测左上与右下角热力图的方式 , 在每帧图像中得到一个最优的边界框 , 并且可以直接在GPU端运行 。

文章插图
简单说就是 , 在我们通过X-VLM确定要追踪的目标以后 , Stark就像钢铁侠Tony Stark的追踪系统一样 , 会记录对象在静止状态和动态状态下的样子 , 处理分析之后实现追踪动态对象 。
那么 , 讲到这里 , 我们已经基本明白这语音玩原神三大技术的原理 。那角色是怎么动起来执行战术的呢?
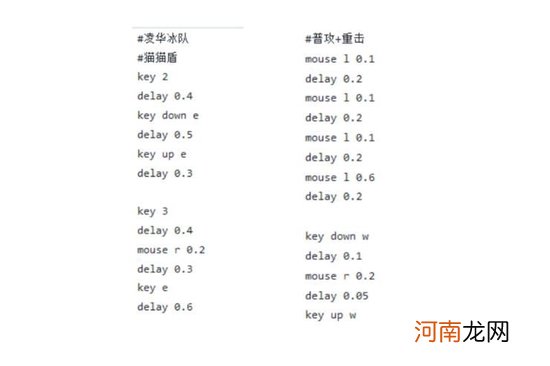
其实实现角色自动攻击、释放技能这一块 , 反而是AI语音玩原神中最容易实现的一个环节 。这个功能可以通过宏指令或者代码编程来实现 。小编特意到作者分享的代码文件中瞄了一眼 , 下面是部分代码的展示 。
文章插图
这一段操作代码使用python写的 , 逻辑也相当的简单 , 就是执行一串预设好的按键指令 。上面图片展示的应该是对应战术一的操作 。其中key跟mouse后面的数字或者字母对应了切换角色和释放技能 。

文章插图
代码也解释了为啥角色执行完战术之后就杵在原地发呆 , 因为没有了后续的指令和输入 。
总的来说 , 如果有小伙伴想简单尝鲜一下这个AI语音玩原神 , 可以直接下载作者分享的代码 , 运行程序即可 。你只需将英雄阵容及顺序设计成和作者一样 , 就可以达到作者视频展示的的效果了 。
- 湘菜特色
- aswl是什么梗
- 电磁炉对人有危害吗 电磁炉对人有副作用吗
- 中信银行的单币信用卡是一种什么卡 中信银行双币信用卡怎么免年费
- 怎样使用微信分身 怎样使用微信
- 智能家居十大排行榜,国内十大最好用智能家居?
- 韩国气垫排行榜10强,韩国什么气垫粉底液好用?
- 税收执法责任制概念 税收执法责任制的作用
- 吃葡萄干的八大好处,葡萄与葡萄干作用的区别?
- 哪个牌子的被套好,婚庆床上用品十大品牌?